Integração de Processamento de Linguagem Natural, Machine Learning e IA Generativa para Gestão de Respostas Automáticas em E-Commerce.
L. G. G. Pimenta
Este projeto utiliza o dataset público da Olist, para construir uma solução de inteligência de dados sobre 40.977 avaliações de consumidores. O objetivo é demonstrar como técnicas de NLP (Natural Language Processing) e Machine Learning podem ser integradas para automatizar a triagem de mensagens e gerar respostas automáticas em massa.
CARACTERÍSTICAS DO PROJETO:
- Otimização de Performance: Processamento paralelo escalável (Multi-core)
-
Arquitetura Generativa (RAG): Implementação de Retrieval-Augmented
Generation com busca semântica via banco vetorial (FAISS) e
SentenceTransformers. -
Explicabilidade (XAI): Análise de impacto de variáveis utilizando
SHAP(SHapley Additive exPlanations) para identificar os termos determinantes nas predições. - Métricas de Robustez: AUC-ROC (0.92), F1-Score estratificado e análise de similaridade por distância euclidiana (L2) no espaço vetorial.
- Integração de Diferentes Modelos: Resultados de medidas estatísticas são entregues diretamente de um modelo para outro, funcionando como "trava de segurança" e como contexto para as respostas automatizadas.
1.1 - O Pipeline
Neste projeto utilizamos: Machine Learn (ML), Natural Language Processing (NLP) e IA Generativa.
1.1.1 - NLP e IA Genertiva
O NLP (Processamento de Linguagem Natural) é o conjunto de processos que dá origem à nossa "matemática linguística". Através de suas técnicas, realizamos a limpeza dos dados — incluindo a remoção de stopwords e a lematização via biblioteca spaCy — para transformar textos em vetores numéricos (embeddings). É nesse espaço vetorial que calculamos as distâncias semânticas utilizando o modelo SentenceTransformer (MiniLM). Para mitigar alucinações e garantir resultados alinhados ao histórico da empresa, implementamos a arquitetura RAG (Retrieval-Augmented Generation): o sistema realiza uma busca por similaridade em nosso banco de dados (via biblioteca FAISS) e fornece os casos reais como contexto para que a IA local (Llama 3) redija uma resposta personalizada. Todo este fluxo, desde a recuperação de dados até a construção do prompt, é orquestrado pela biblioteca LangChain.
1.1.2 - ML
A camada de Machine Learning (ML) inicia-se na transformação do dataset em uma Matriz de Importância via TfidfVectorizer (Scikit-learn). Cada linha representa uma reclamação, onde os termos são convertidos em pesos estatísticos: o valor é proporcional à frequência da palavra na reclamação, mas inversamente ao quanto ela aparece no Corpus. O XGBoost atua na interpretação desses padrões; ele processa as colunas da matriz para aprender quais combinações de pesos indicam determinados review_scores. O modelo é então treinado para calcular a probabilidade de uma nova entrada corresponder a um cenário de insatisfação, utilizando processamento paralelo em 8 núcleos para garantir rapidez e eficiência nessa análise preditiva.
1.1.3 - Dados
O dataset foi obtido na plataforma Kaggle (link para download na bibliografia) e é constituído de vários arquivos. Neste projeto, utilizamos exclusivamente o arquivo olist_order_reviews_dataset.csv, pois nele residem os scores e as mensagens de texto dos clientes. Como a modelagem de Machine Learning requer dados etiquetados, filtramos apenas os registros que continham tanto a avaliação quanto o comentário, resultando em um total de 40.977 registros.
- review_comment_message: Comentários reais do cliente sobre o produto, abrangendo desde reclamações críticas (ex: produto danificado) até elogios (ex: entrega rápida).
- review_score: Nota de 1 a 5 atribuída pelo cliente, servindo como a etiqueta (label) fundamental para o treinamento supervisionado do modelo.
ETL (Extraction, Transform and Load)
2.1 - Limpando Dados
Reunimos as três features de interesse em um só dataframe (score, mensagem e target), sendo target uma feature binária criada por nós, onde o valor 0 representa scores 4 ou 5 (target = 0, cliente satisfeito) e o valor 1 representa os demais (target = 1, cliente insatisfeito). Utilizamos a biblioteca spaCy para a limpeza dos dados, realizando a remoção de stopwords, conversão para lower case e o processo de lematização — que normaliza variações como "atrasou", "atrasado" e "atrasaram" para um radical único. As linhas vazias resultantes deste processo de tratamento foram excluídas.
Ao fim da limpeza, o dataset consolidou 39.528 registros, distribuídos em uma proporção de 64% de avaliações positivas (target = 0) e 36% de avaliações negativas (target = 1), configurando um cenário realista de dados desbalanceados para o modelo.
Código:Data Cleaning - Python
import os
import pandas as pd
import spacy
from collections import Counter
# Setando hardware e caminhos de arquivos
N_CORES = 8
DATA_PATH = "DATA/olist_order_reviews_dataset.csv"
def carregar_e_limpar_dados(path):
if not os.path.exists(path):
raise FileNotFoundError(f"Arquivo nao encontrado em: {path}")
df = pd.read_csv(path)
# Filtramos os registros que não contem mensagens
df = df.dropna(subset=['review_comment_message'])
# Aqui salvamos o resultado do teste lógico: se a nota dada ao
# cliente é <= 3 então resultado é True (1), caso contrário é 0.
df['target'] = (df['review_score'] <= 3).astype(int)
return df[['review_comment_message', 'target']].copy()
if __name__ == "__main__":
try:
print(f"Iniciando processamento de registros.")
df = carregar_e_limpar_dados(DATA_PATH)
# Setup do spaCy para processamento em partes.
nlp = spacy.load("pt_core_news_lg", disable=["ner", "parser"])
print(f"Processando textos com nlp.pipe em {N_CORES} cores...")
# Usamos o nlp.pipe pois ele lida melhor com grandes volumes e evita o erros de buffer
texts = df['review_comment_message'].astype(str).tolist()
processed_texts = []
for doc in nlp.pipe(texts, n_process=N_CORES, batch_size=1000):
# Aqui nós retiramos stopwords e deixamos tudo em minúsculo
tokens = [token.text.lower() for token in doc if token.is_alpha and not token.is_stop]
processed_texts.append(" ".join(tokens))
df['text_clean'] = processed_texts
# Algumas linha ficam vazias depois da limpeza, abaixo nós fazemos
# a remoção dessas linhas.
df = df[df['text_clean'] != ""]
# Verificamos algumas características do dataframe final obtido.
all_words = " ".join(df['text_clean']).split()
common_words = Counter(all_words).most_common(10)
print("\n--- Relatorio de Preprocessamento ---")
print(f"Top 10 palavras mais frequentes: {common_words}")
print(f"Distribuicao das Classes Target (0=Neg, 1=Pos):")
print(df['target'].value_counts(normalize=True))
# Salvando o dataset.
df.to_csv("dataset_processed.csv", index=False)
print(f"\nSucesso! {len(df)} registros salvos em 'dataset_processed.csv'.")
except Exception as e:
print(f"Erro durante a execucao: {e}")
Output Código Data cleaning
2.2 - Treinamento
Durante o treinamento do XGBoostClassifier, otimizamos o tempo de processamento utilizando os 8 núcleos disponíveis da CPU. Para equilibrar a performance com a explicabilidade do modelo, limitamos o vocabulário a 2.000 features durante a vetorização por TF-IDF. Além disso, aplicamos a técnica de RandomizedSearchCV para realizar uma busca num espaço predeterminado de hiperparâmetros, garantindo a seleção da combinação que resultasse na melhor AUC-ROC para os dados de teste.
Código treinamento - Python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import joblib
import shap
from sklearn.model_selection import train_test_split, RandomizedSearchCV
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import (
classification_report,
roc_auc_score,
ConfusionMatrixDisplay,
precision_recall_curve,
PrecisionRecallDisplay
)
from xgboost import XGBClassifier
print("Carregando dados")
df = pd.read_csv("dataset_processed.csv")
# Excluindo qualquer observação com "na's"
df = df.dropna(subset=['text_clean'])
# Amostragem treino/teste, estratificada
X = df['text_clean']
y = df['target']
X_train_raw, X_test_raw, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# Vetorização TF-IDF
print("Vetorizando textos...")
vectorizer = TfidfVectorizer(max_features=2000, ngram_range=(1, 2))
X_train = vectorizer.fit_transform(X_train_raw)
X_test = vectorizer.transform(X_test_raw)
# OTIMIZAÇÃO DE HIPERPARÂMETROS (RANDOMIZED SEARCH)
print("Iniciando busca de hiperparâmetros (30 tentativas nos 8 núcleos)...")
# Espaço de possibilidades (Hiperparâmetros)
param_dist = {
'n_estimators': [100, 300, 500],
'max_depth': [3, 6, 10],
'learning_rate': [0.01, 0.1, 0.2],
'subsample': [0.7, 0.8, 0.9]
}
# Modelo base
xgb_base = XGBClassifier(
n_jobs=8,
random_state=42,
use_label_encoder=False,
eval_metric='logloss'
)
# Buscador aleatório com Validação Cruzada (CV=3)
random_search = RandomizedSearchCV(
estimator=xgb_base,
param_distributions=param_dist,
n_iter=10,
cv=3,
n_jobs=8,
random_state=42,
verbose=1
)
random_search.fit(X_train, y_train)
# Definindo o melhor modelo após a busca
model = random_search.best_estimator_
print(f"\nMelhores parâmetros encontrados: {random_search.best_params_}")
# Analisando resultados
preds = model.predict(X_test)
probs = model.predict_proba(X_test)[:, 1]
print("\n--- Métricas de Performance ---")
print(classification_report(y_test, preds))
print(f"AUC-ROC Score: {roc_auc_score(y_test, probs):.4f}")
# Matriz de Confusão
print("\nGerando Matriz de Confusão...")
fig, ax = plt.subplots(figsize=(8, 6))
ConfusionMatrixDisplay.from_predictions(
y_test,
preds,
display_labels=['Satisfação', 'Insatisfação'],
cmap='Blues',
ax=ax
)
plt.title("Matriz de Confusão: Classificação de Risco")
plt.savefig("matriz_confusao.png")
# Curva Precision-Recall
print("Gerando Curva Precision-Recall...")
plt.figure(figsize=(8, 6))
precision, recall, _ = precision_recall_curve(y_test, probs)
disp = PrecisionRecallDisplay(precision=precision, recall=recall)
disp.plot(color="darkorange")
plt.title("Curva Precision-Recall (Foco na Classe 1)")
plt.grid(True, linestyle='--', alpha=0.6)
plt.savefig("precision_recall_curve.png")
# Explicabilidade (SHAP)
print("Gerando análise de explicabilidade (SHAP)...")
# Amostragem aleatória para o SHAP para representar melhor o dataset
indices_aleatorios = np.random.choice(X_test.shape[0], 500, replace=False)
X_sample = X_test[indices_aleatorios].toarray()
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_sample)
plt.figure(figsize=(10, 6))
shap.summary_plot(
shap_values,
X_sample,
feature_names=vectorizer.get_feature_names_out(),
plot_type="bar",
show=False
)
plt.title("Impacto das Palavras na Decisão do Modelo (SHAP)")
plt.savefig("feature_importance_shap.png")
print("\nSalvando modelos pkl para uso no Script 03...")
joblib.dump(model, "legal_model_xgb.pkl")
joblib.dump(vectorizer, "tfidf_vectorizer.pkl")
print("Processo concluído com sucesso!")
Output treinamento - Python
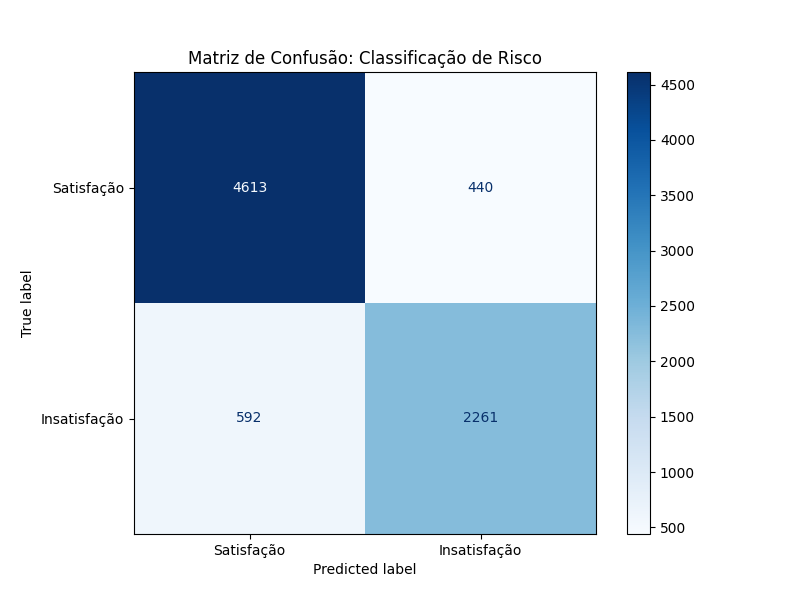
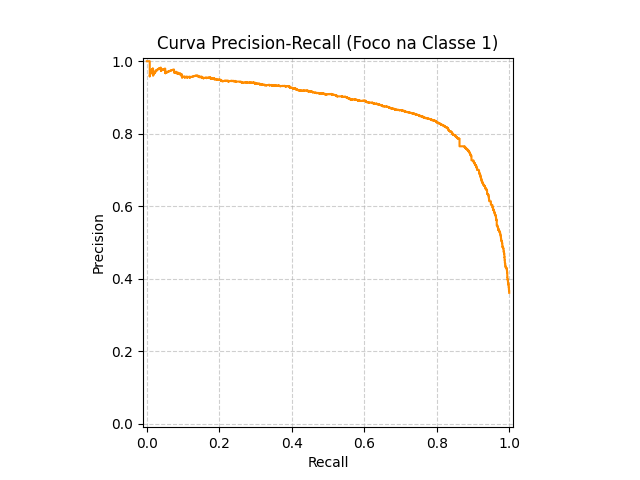
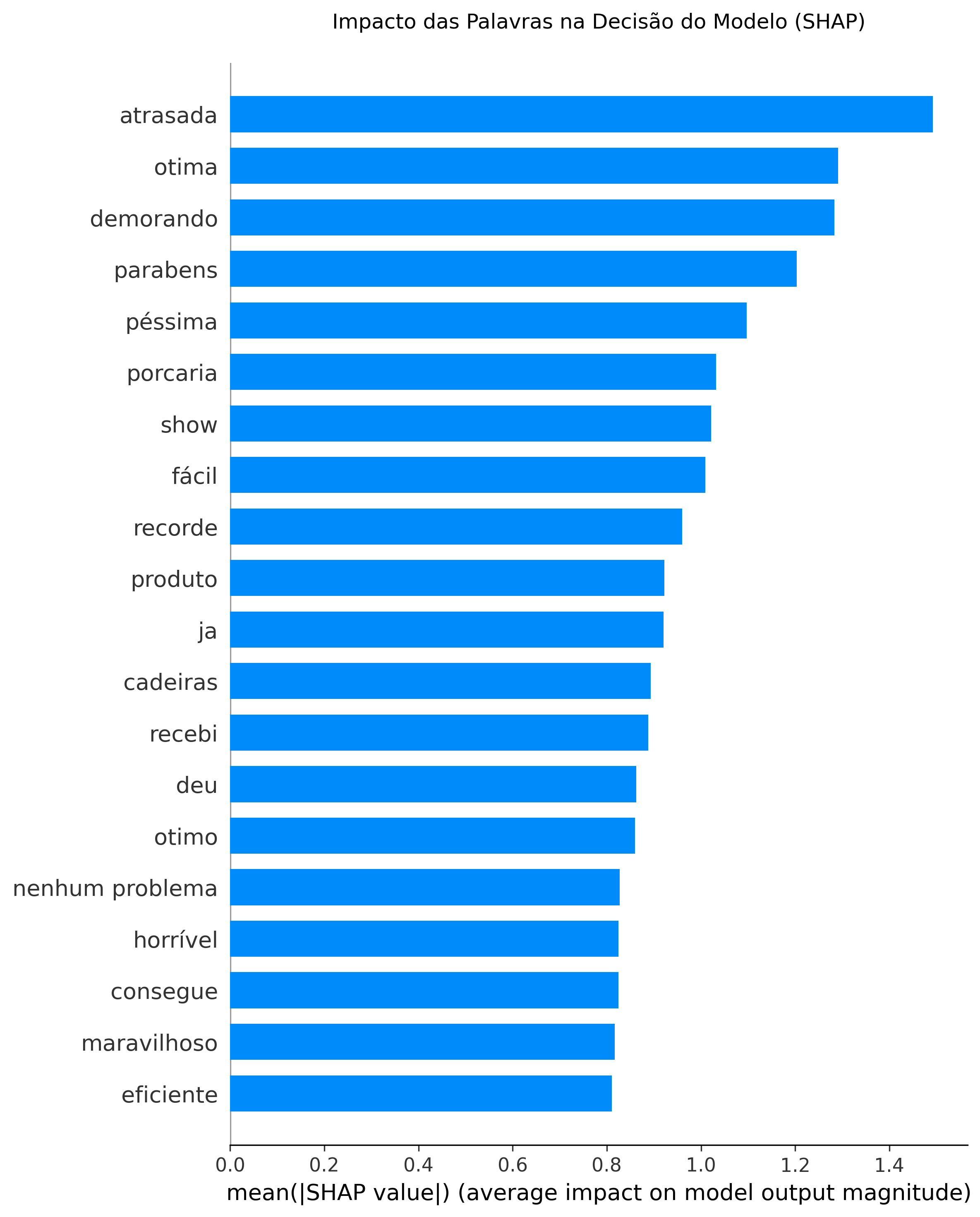
Após treino e teste, obtivemos um AU-ROC score de 0,9255, o que, como veremos adiante, entregará uma grande segurança para o Llama 3 formular corretamente uma mensagem de resposta personalizada para o cliente. Obtivemos também um F1-score de 0,9 para negativos (cliente satisfeito) e 0,81 para positivos (clientes insatisfeitos), demonstrando um alto equilíbrio entre precisão e sensibilidade. Seguem abaixo os gráficos de Matriz de Confusão, Curva Precision-Recall e um gráfico para análise de explicabilidade (SHAP), que detalham o comportamento do modelo.
2.3 - Integração com IA Generativa
Depois de treinado e testado nosso modelo de ML, partimos para a integração com uma IA Generativa instalada localmente; neste projeto, utilizamos a Llama 3, que é gratuita e de fácil manipulação. Também fizemos questão de paralelizar a computação nesta fase, utilizando os 8 núcleos da CPU, pois esta é a etapa que mais consome tempo de processamento.
Para otimizar a performance, carregamos uma amostra estratégica de 5.000 mensagens, entre as quais realizamos uma busca utilizando a biblioteca FAISS para selecionar os registros mais próximos semanticamente da entrada fornecida pelo cliente.
Após inserirmos a mensagem do cliente como input, as três tarefas fundamentais executadas pelo sistema são:
- Busca RAG: Realizamos a busca de mensagens com semelhança semântica transformando cada frase em um vetor de 384 dimensões (via modelo paraphrase-multilingual-MiniLM-L12-v2). A biblioteca FAISS calcula a distância geométrica (L2) entre o vetor da "nova reclamação" e os demais da amostra, extraindo as duas mensagens mais semelhantes.
- Classificação XGBoost: A mensagem de input é processada pelo modelo treinado para classificar o sentimento entre satisfação ou insatisfação, calculando simultaneamente a probabilidade percentual (intensidade) da predição.
- Integração: O contexto recuperado, a classificação e a intensidade do sentimento são integrados ao prompt estruturado entregue para a Llama 3. Isso permite que a IA elabore uma resposta baseada não apenas em seu conhecimento prévio, mas no contexto real e situacional fornecido pelos dados.
Com estes três passos, aumentamos significativamente a qualidade das respostas geradas e mitigamos o risco de alucinações por parte da IA.
Código Integração de Modelos - Python
import joblib
import pandas as pd
import numpy as np
import faiss
import os
from sentence_transformers import SentenceTransformer
from langchain_ollama import OllamaLLM
os.environ["OMP_NUM_THREADS"] = "8"
# Carregando de Recursos
print("Carregando Modelos e Banco de Dados...")
df = pd.read_csv("dataset_processed.csv")
model_xgb = joblib.load("legal_model_xgb.pkl")
tfidf = joblib.load("tfidf_vectorizer.pkl")
print("Carregando modelo de linguagem (SentenceTransformer)")
embedder = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
# Criação do Index de Busca (FAISS)
print("Vetorizando amostra para RAG")
df_sample = df.sample(5000, random_state=42).reset_index(drop=True)
embeddings = embedder.encode(df_sample['text_clean'].tolist(), show_progress_bar=True)
d = embeddings.shape[1]
index = faiss.IndexFlatL2(d)
index.add(np.array(embeddings).astype('float32'))
def consultar_ia(nova_reclamacao):
# Predição do Modelo (XGBoost) - A "Intensidade"
text_vector = tfidf.transform([nova_reclamacao])
prob_negativa = model_xgb.predict_proba(text_vector)[0][1]
# Busca RAG (Similaridade Semântica)
query_embedding = embedder.encode([nova_reclamacao])
D, I = index.search(np.array(query_embedding).astype('float32'), k=2)
contexto = df_sample.iloc[I[0]]['review_comment_message'].values
# Lógica de Intensidade para o Prompt
intensidade = "CRÍTICA" if prob_negativa > 0.70 else "MODERADA"
# Llama3 recebe o score do XGBoost para ajustar o tom da resposta automática
prompt = f"""
BASEANDO-SE NAS SEGUINTES INFORMAÇÕES:
DADOS DO MODELO ESTATISTICO (XGBoost):
- Alerta de Insatisfacao do Cliente: {intensidade}
- Nivel de Intensidade: {prob_negativa*100:.2f}%
RECLAMACAO DO CLIENTE: "{nova_reclamacao}"
CASOS SIMILARES JÁ OCORRIDOS ANTERIORMENTE:
1. {contexto[0]}
2. {contexto[1]}
EXECUTE AS SEGUINTES TAREFAS:
1. Classifique o problema em: Entrega, Integridade, Financeiro, Atendimento, Sistema.
2. Redija uma resposta para o cliente ponderada pelo "Alerta de Insatisfacao do Cliente",
"Nivel de Intensidade" e "CASOS SIMILARES 1 e 2 JÁ OCORRIDOS ANTERIORMENTE".
"""
print("\n" + "="*50)
print("--- ANÁLISE HÍBRIDA (XGBOOST + RAG + LLM) ---")
print("="*50)
print(f"Probabilidade XGBoost: {prob_negativa*100:.2f}% ({intensidade})")
print("\nSolicitando geração ao Llama 3...")
try:
llm = OllamaLLM(model="llama3", temperature=0.1)
resposta = llm.invoke(prompt)
print("\n--- RESPOSTA DA IA ---")
print(resposta)
except Exception as e:
print(f"\nErro ao conectar com Ollama: {e}")
if __name__ == "__main__":
# Teste com uma frase que deve disparar o alerta do seu modelo
reclamacao_teste = "Meu produto não foi entregue até hoje. Já paguei mas não chegou."
consultar_ia(reclamacao_teste)
Output Integração de Modelos - Python
A implementação do modelo XGBoost, aliada ao processamento paralelo de 8 núcleos, alcançou um AUC-ROC de 0,92 e F1-Score de 0,90 para clientes satisfeitos. A análise de explicabilidade via SHAP confirmou a precisão do pipeline de NLP ao identificar gatilhos semânticos críticos como 'atrasada', 'péssima' e 'demorando' como os principais termos de insatisfação. Essa acurácia estatística serviu como uma 'trava de segurança' essencial, garantindo que a triagem automatizada operasse com total confiança antes de encaminhar os dados para a camada generativa.
A integração da arquitetura RAG (Retrieval-Augmented Generation) com o modelo Llama 3 local permitiu a geração de respostas personalizadas e contextuais, mitigando o risco de alucinações da IA. Ao utilizar o banco vetorial FAISS para recuperar casos históricos semelhantes, o sistema foi capaz de modular o tom da comunicação para situações de alta probabilidade de crise (intensidade crítica > 70%). O resultado final é um ecossistema de atendimento preventivo que não apenas automatiza a triagem, mas entrega uma resolução estratégica que reduz o tempo de resposta e previne potenciais escaladas de crise.
Esse projeto apresenta inúmeros potenciais a serem explorados, como o acionamento automático de determinados setores do time de operação através da triagem e classificação da mensagem do cliente e a utilização de outras informações (histórico do cliente/vendedor, dados sobre rastreamento da enterga, etc) na construção do contexto para formulação de uma resposta ainda mais interessante.
Downloads e Links
Repositório GitHub- BROWNLEE, Jason. XGBoost With Python: Gradient Boosted Trees With XGBoost and scikit-learn. Edition v1.15. Machine Learning Mastery, 2020.
- Matthew Wiens, Alissa Verone-Boyle, Nick Henscheid, Jagdeep T. Podichetty, Jackson Burton. A Tutorial and Use Case Example of the eXtreme Gradient Boosting (XGBoost) Artificial Intelligence Algorithm for Drug Development Applications. Disponível em: ascpt.onlinelibrary.wiley.com . (Acesso em: 05 mar. 2026)
- Olist and 3 collaborators Brazilian E-Commerce Public Dataset by Olist. Disponível em: https://www.kaggle.com/datasets/olistbr/brazilian-ecommerce?select=olist_order_reviews_dataset.csv . (Acesso em: 05 mar. 2026)