Prevenção de Fraudes - XGBoost.
L. G. G. Pimenta
Neste projeto utilizando Machine Learning construi um pipeline de ponta a ponta para a detecção de fraudes em transações realizadas com cartões de crédito.
CARACTERÍSTICAS DO PROJETO:
- Machine Learning: XGBoost.
- Otimização de performance: Ingestão via chunking, medallion architecture, camada de persistência (MySQL) e computação em paralelo.
-
Refinamento:
Seleção de hiperparâmetros via
RandomizedSearchCVcom validação cruzada estratificada. - Regras de negócio: Análise de impacto de features.
- Métricas: AUPRC (Area Under the Precision-Recall Curve) e Matriz de confusão.
1.1 - XGBoost
Porque utilizar XGBoost? O Xtreme Gradient Boosting (XGBoost) trata-se de uma implementação de árvores de decisão com gradient boosting. Este algorítmo ganhou reconhecimento pela sua alta velocidade e desempenho. Além de ser bem posicionado em publicações de benchmarks, quando falamos de dados estruturados ou tabulares (como em nosso caso) o XGBoost domina sendo a escolha preferida em competições como as que acontecem na plataforma Kaggle. Por fim árvores de decisão são melhores em segregar dados multidimensionais conseguindo captar encadeamentos lógicos inerentes de comportamentos não lineares entre as variáveis o que uma regressão logística por exemplo não performa.
1.2 - Dataset
Os dados foram obtidos da plataforma Kaggle (link para download na bibliografia). O Credit Card Fraud Detection é disponibilizado na forma de um .csv com 284807 observações e 31 colunas. Este dataset contém dados sobre transações (fraudulentas e genuínas) realizadas com cartões de crédito ao longo de um período de 48 horas em setembro de 2013.
O dataset é anonimizado de modo que a maioria das colunas (V1 a V28) são componentes numéricas resultantes de uma transformação PCA (Principal Component Analysis). As únicas variáveis não transformadas são:
- Time: Segundos decorridos desde a primeira transação.
- Amount: Valor da compra realizada com o cartão.
Uma característica importante deste dataset é o seu desbalanceamento: 284315 transações genuinas e apenas 492 fraudulentas. Esse alto grau de desbalancemaneto é muito comum em conjuntos de dados dessa natureza.
ETL (Extraction, Transfom and Load)
2.1 - Carregamento dos Dados
Para acelerar o processo de desenvolvimento os dados foram carregados num banco MySQL, assim qualquer manipulação mais complexa que viesse a ser necessária poderia fazer uso do motor do MySQL ou mesmo alguma consulta mais simples poderia ser realizada sem que fosse necessário escrever um código python.
O carregamento foi feito via chunking para garantir que o processo consumisse uma quantidade de RAM adequada para nosso hardware.
Código:Código de carregamento - Python
import pandas as pd
from sqlalchemy import create_engine
import os
from dotenv import load_dotenv
load_dotenv()
USER = os.getenv('DB_USER')
PASSWORD = os.getenv('DB_PASSWORD')
HOST = os.getenv('DB_HOST')
DATABASE = os.getenv('DB_NAME')
def get_engine():
return create_engine(f'mysql+pymysql://{USER}:{PASSWORD}@{HOST}/{DATABASE}')
def carregar_tabela(file_path, table_name):
if not os.path.exists(file_path):
print(f"Arquivo nao encontrado: {file_path}")
return
print(f"Iniciando processamento sequencial: {table_name}")
engine = get_engine()
chunk_size = 20000
try:
reader = pd.read_csv(file_path, chunksize=chunk_size)
total_rows = 0
for i, chunk in enumerate(reader):
mode = 'replace' if i == 0 else 'append'
chunk.to_sql(
name=table_name,
con=engine,
if_exists=mode,
index=False
)
total_rows += len(chunk)
if (i + 1) % 5 == 0:
print(f"Tabela {table_name}: {total_rows} linhas ja inseridas...")
print(f"Sucesso: {table_name} finalizada com {total_rows} linhas.")
except Exception as e:
print(f"Erro ao carregar a tabela {table_name}: {e}")
if __name__ == "__main__":
base_path = 'data2/Credit Card Fraud Detection/'
tarefas = [
(os.path.join(base_path, 'creditcard.csv'), 'transactions')
]
print("Iniciando processo de carga sequencial.")
for arquivo, tabela in tarefas:
carregar_tabela(arquivo, tabela)
print("Processo completo. Todos os dados estao no MySQL.")
print("\n" + "="*50)
print("CARACTERÍSTICAS DA TABELA")
print("="*50)
try:
engine = get_engine()
colunas = pd.read_sql("DESCRIBE transactions",engine)
df_estrutura = pd.read_sql("SELECT * FROM transactions LIMIT 5", engine)
total_banco = pd.read_sql("SELECT COUNT(*) as total FROM transactions", engine).iloc[0]['total']
print(f"\nTOTAL DE REGISTROS: {total_banco}")
print(f"TOTAL DE COLUNAS: {len(colunas['Field'])}")
print("\nEstrutura das Colunas (Tipos):")
print(df_estrutura.dtypes.value_counts())
print("Nomes das colunas")
print(",".join(colunas['Field'].tolist()))
print("\n")
except Exception as e:
print(f"Erro ao tentar extrair informações da tabela: {e}")
Output Código de carregamento
2.2 - Engenharia de Features
Foram criadas 3 novas features:
- hour: Hora do dia em que ocorreu a transação. Se deixássemos apenas a coluna Time contando o tempo (em segundos) poderíamos perder algum sinal circadiano nas aplicações de fraudes.
- log_amount: É a mesma coluna Amount (valor da transação) mas depois de passar por uma função logarítimica para suavisar grandes diferenças. Assim nós ajudamos nosso modelo a não focar nos extremos a ponto de deixar de aprender nuances sobre nosso sistema.
- v_sum: Apesar das colunas V_* estarem codificadas, nós adicionamos uma feature com base na soma dessas colunas com o intuito de dar ao modelo a chance de aprender com o efeito do todo que talvez possa não ser encontrado analisando separadamente as partes.
Também criamos as features std_amount e std_time que são simplesmente as colunas Amount e Time escalonadas. Essas duas colunas não haviam sido codificadas e nem tratadas e por isso estavam em um estado bruto. O modelo poderia associar mais ou menos importancia a uma coluna simplesmente por possuir valores de maior magnitude, o que não iria contribuir para a solução do problema.
Após a criação das novas features realizamos novamente o carregamento para o banco MySQL mantendo no entando a tabela com o dataset original inalterada. Apartir de agora nosso banco passou a ter duas camadas (Medallion Architecture) sendo nosso Raw Data a tabela com os dados originais (Camada Bronze) e a tabela com novas features e transformações de escalonamento nosso Enriched Data (Camada Silver: dados limpos e com engenharia de features).
Código transformações e engenharia de features - Python
import os
import pandas as pd
import numpy as np
from sqlalchemy import create_engine, text
from sklearn.preprocessing import RobustScaler
from dotenv import load_dotenv
load_dotenv()
USER = os.getenv('DB_USER')
PASSWORD = os.getenv('DB_PASSWORD')
HOST = os.getenv('DB_HOST')
DATABASE = os.getenv('DB_NAME')
def get_engine():
return create_engine(f'mysql+pymysql://{USER}:{PASSWORD}@{HOST}/{DATABASE}')
def process_with_feature_engineering():
engine = get_engine()
print("1. Lendo dados de 'transactions'...")
df = pd.read_sql("SELECT * FROM transactions", engine)
print("2. Criando novas features...")
df['hour'] = (df['Time'] % 86400) // 3600
df['log_amount'] = np.log1p(df['Amount'])
v_cols = ['V1', 'V3', 'V4', 'V7', 'V10', 'V11', 'V12', 'V14', 'V16', 'V17']
df['v_sum'] = df[v_cols].sum(axis=1)
print("3. Escalonando features...")
scaler = RobustScaler()
df['std_amount'] = scaler.fit_transform(df['Amount'].values.reshape(-1, 1))
df['std_time'] = scaler.fit_transform(df['Time'].values.reshape(-1, 1))
cols_to_drop = ['Time', 'Amount']
df_train = df.drop(cols_to_drop, axis=1)
cols = [c for c in df_train.columns if c != 'Class'] + ['Class']
df_train = df_train[cols]
print(f"4. Salvando em 'train_transactions' ({len(df_train)} linhas)...")
df_train.to_sql('train_transactions', con=engine, if_exists='replace', index=False, chunksize=10000)
print("Nova tabela de treino com Feature Engineering criada!")
if __name__ == "__main__":
process_with_feature_engineering()
Output transformações e engenharia de features - Python
Treinamento e Avaliação do Modelo
2.3 - Treinamento
Para otimizar os resultados do modelo criamos uma função específica para auxiliar na escolha dos hiperparâmetros. Essa função possui as seguintes características:
- scale_pos_weight: Aqui trabalhamos sobre o desbalanceamento do dataset. Com esse hiperparâmetro podemos dizer ao modelo que devemos dar mais peso as raras fraudes uma vez que ele irá se deparar com poucas delas durante o treinamento.
- param_dist: Foi criado um espaço amostral de hiperparâmetros para otimização via Randomized Search. Essa abordagem permite explorar um número controlado de combinações.
- StratifiedKFold: Essa é a validação cruzada estratificada. Nós dividimos o dataset em três partes (respeitando as proporções de fraudes e não fraudes) e então utilizamos duas partes para treino e a terceira e última para teste, assim com apenas um dataset podemos treinar o modelo três vezes. Esse processo foi realizado para todas as 10 combinações de Hiperparâmetros.
- Otimização de Hardware: Configuração do algoritmo para processamento paralelo utilizando o parâmetro n_jobs=8. Ao distribuir o cálculo entre os 8 núcleos da CPU, reduzimos drasticamente o tempo de treinamento (Training Latency), permitindo iterações mais rápidas durante o ciclo de desenvolvimento.
Após os 30 treinos (10 combinações × 3 folds), a função retorna apenas o modelo que obteve o maior score médio de AUPRC, pronto para ser usado no script principal.
O critério de seleção para o melhor modelo foi a AUPRC (Area Under the Precision-Recall Curve). Em cenários de fraude, esta métrica é superior à Acurácia ou ao ROC-AUC, pois foca exclusivamente na capacidade do modelo em identificar corretamente a classe positiva (fraude) sob condições de alta raridade
Código Função de Otimização - Python
import numpy as np
from xgboost import XGBClassifier
from sklearn.model_selection import RandomizedSearchCV, StratifiedKFold
from sklearn.metrics import make_scorer, average_precision_score
import pandas as pd
import os
PASTA_SAIDA = "RESULTADOS_MODELO"
def otimizar_hyperparametros(X_train, y_train):
print("--- Iniciando Busca de Hiperparametros (Otimizacao) ---")
pos_weight = (y_train == 0).sum() / (y_train == 1).sum()
param_dist = {
'n_estimators': [400, 500],
'max_depth': [4, 5, 6],
'learning_rate': [0.05, 0.1],
'subsample': [0.85, 0.9],
'colsample_bytree': [0.8, 0.85],
'gamma': [0, 0.1, 0.2],
'reg_lambda': [1, 2, 5],
'reg_alpha': [0],
'scale_pos_weight': [pos_weight]
}
xgb = XGBClassifier(
tree_method='hist',
random_state=42,
n_jobs=1
)
skf = StratifiedKFold(n_splits=3, shuffle=True, random_state=42)
scorer = make_scorer(average_precision_score, response_method='predict_proba')
random_search = RandomizedSearchCV(
estimator=xgb,
param_distributions=param_dist,
n_iter=10,
scoring=scorer,
cv=skf,
verbose=3,
random_state=42,
n_jobs=8
)
print("Iniciando fit... Verifique o uso de CPU.")
random_search.fit(X_train, y_train)
df_resultados = pd.DataFrame(random_search.cv_results_)
colunas_interesse = [
'param_n_estimators',
'param_max_depth',
'param_learning_rate',
'mean_test_score',
'std_test_score',
'mean_fit_time'
]
tabela_performance = df_resultados[colunas_interesse].sort_values(by='mean_test_score', ascending=False)
tabela_performance.to_csv(os.path.join(PASTA_SAIDA, "tuning_results.csv"), index=False)
print("\n" + "="*80)
print("RANKING DE PERFORMANCE DO TUNING (TOP 10 COMBINAÇÕES)")
print("="*80)
print(tabela_performance.to_string(index=False, formatters={'mean_test_score': '{:,.4f}'.format, 'mean_fit_time': '{:,.2f}s'.format}))
print("="*80)
print(f"Melhor Score (AUPRC): {random_search.best_score_:.4f}")
return random_search.best_estimator_
Código Treinamento - Python
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import joblib
from sqlalchemy import create_engine
from xgboost import XGBClassifier, plot_importance
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix, average_precision_score, PrecisionRecallDisplay
from dotenv import load_dotenv
from otimizador import otimizar_hyperparametros
load_dotenv()
USER, PASSWORD, HOST, DATABASE = os.getenv('DB_USER'), os.getenv('DB_PASSWORD'), os.getenv('DB_HOST'), os.getenv('DB_NAME')
engine = create_engine(f"mysql+pymysql://{USER}:{PASSWORD}@{HOST}/{DATABASE}")
PASTA_IMG = "RESULTADOS_MODELO"
def garantir_pasta():
if not os.path.exists(PASTA_IMG):
os.makedirs(PASTA_IMG)
print(f"Pasta {PASTA_IMG} criada.")
def exportar_artefatos(model):
garantir_pasta()
print("--- Exportando modelo treinado ---")
model.save_model(os.path.join(PASTA_IMG, "modelo_fraud_xgb.json"))
joblib.dump(model, os.path.join(PASTA_IMG, "modelo_final.pkl"))
print(f"Modelo salvo na pasta {PASTA_IMG}")
def treinar_modelo_fraude():
garantir_pasta()
print("--- Lendo dados de treino do MySQL ---")
df = pd.read_sql("SELECT * FROM train_transactions", engine)
X = df.drop('Class', axis=1)
y = df['Class']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
model = otimizar_hyperparametros(X_train, y_train)
print("--- Treinamento Final com Melhores Parâmetros ---")
model.fit(X_train, y_train, eval_set=[(X_test, y_test)], verbose=False)
y_pred = model.predict(X_test)
y_proba = model.predict_proba(X_test)[:, 1]
print("Salvando Matriz de Confusão...")
plt.figure(figsize=(10, 7))
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', cbar=False)
plt.title('Matriz de Confusão - XGBoost', fontsize=15)
plt.ylabel('Realidade')
plt.xlabel('Previsão do Modelo')
plt.savefig(os.path.join(PASTA_IMG, "01_matriz_confusao.png"), dpi=300)
plt.close()
print("Salvando Curva Precision-Recall...")
plt.figure(figsize=(10, 7))
display = PrecisionRecallDisplay.from_estimator(model, X_test, y_test)
display.ax_.set_title("Curva Precision-Recall (AUPRC)", fontsize=15)
plt.savefig(os.path.join(PASTA_IMG, "02_curva_precision_recall.png"), dpi=300)
plt.close()
print("Salvando Feature Importance...")
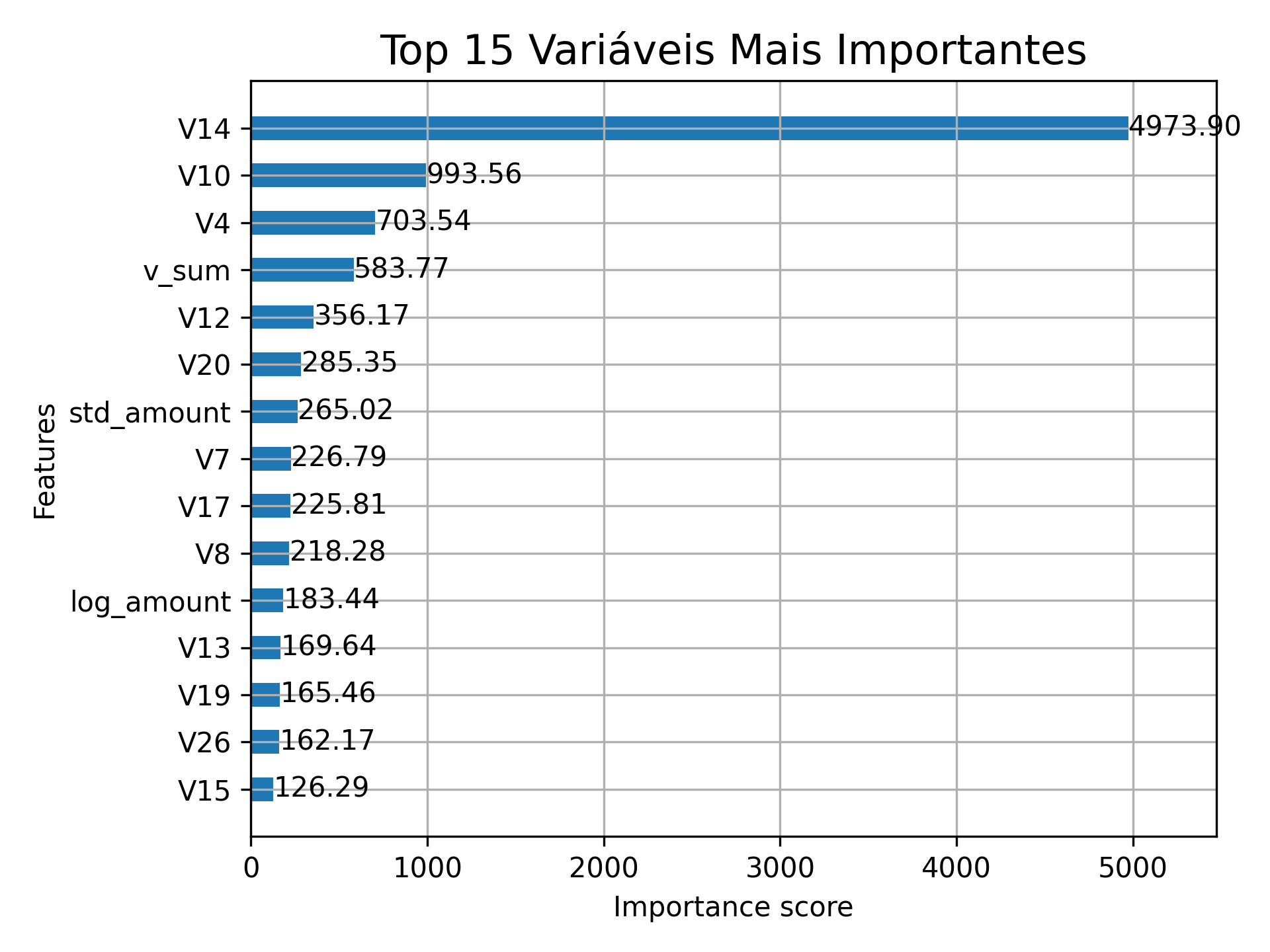
plt.figure(figsize=(12, 10))
plot_importance(model, importance_type='gain', max_num_features=15, height=0.5,values_format="{v:.2f}")
plt.title("Top 15 Variáveis Mais Importantes", fontsize=15)
plt.tight_layout()
plt.savefig(os.path.join(PASTA_IMG, "03_feature_importance.png"), dpi=300)
plt.close()
print("\n--- Relatório Final ---")
print(classification_report(y_test, y_pred))
auprc = average_precision_score(y_test, y_proba)
print(f"Área sob a Curva Precision-Recall (AUPRC): {auprc:.4f}")
return model
if __name__ == "__main__":
modelo_final = treinar_modelo_fraude()
exportar_artefatos(modelo_final)
Output Função de Otimização e Treinamento - Python
2.4 - Avaliação
Usando o script de otimização nós encontramos uma melhor combinação de hiperparâmetros resultante em um AUPRC de 0.8526, e após o teinamento já nos dados de teste obtivemos um AUPRC de 0.8870. A proximidade entre estes dois resultados sinalizam que nosso modelo não está passando por algum problema de Overfitting.
A Matriz de Confusão mostra que o modelo identificou corretamente 82 transações fraudulentas com um volume baixíssimo de falsos positivos (apenas 12 em quase 57mil casos). Essa eficácia é reforçada pela Curva Precision-Recall, que apresenta um AP (Average Precision) de 0.89, indicando que o modelo consegue manter uma alta taxa de acerto (precisão) mesmo buscando capturar o máximo de fraudes possível (recall), o modelo quase não acusa transações legítimas. Por fim, o gráfico de Feature Importance destaca que a variável V14 é, isoladamente, o principal fator de decisão do algoritmo, possuindo um ganho de informação significativamente superior às demais, seguida por variáveis como V10 e a feature de engenharia própria v_sum.
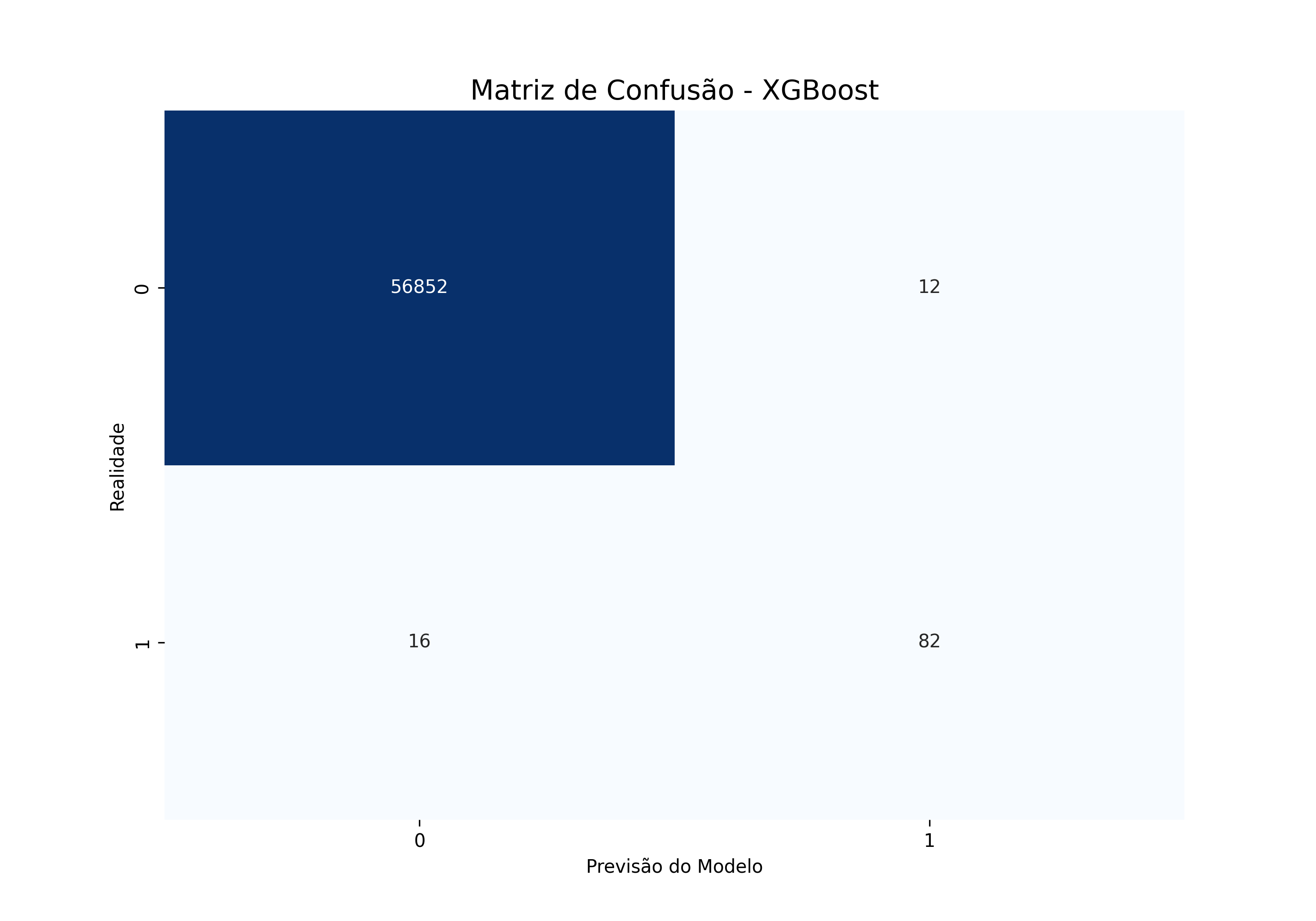
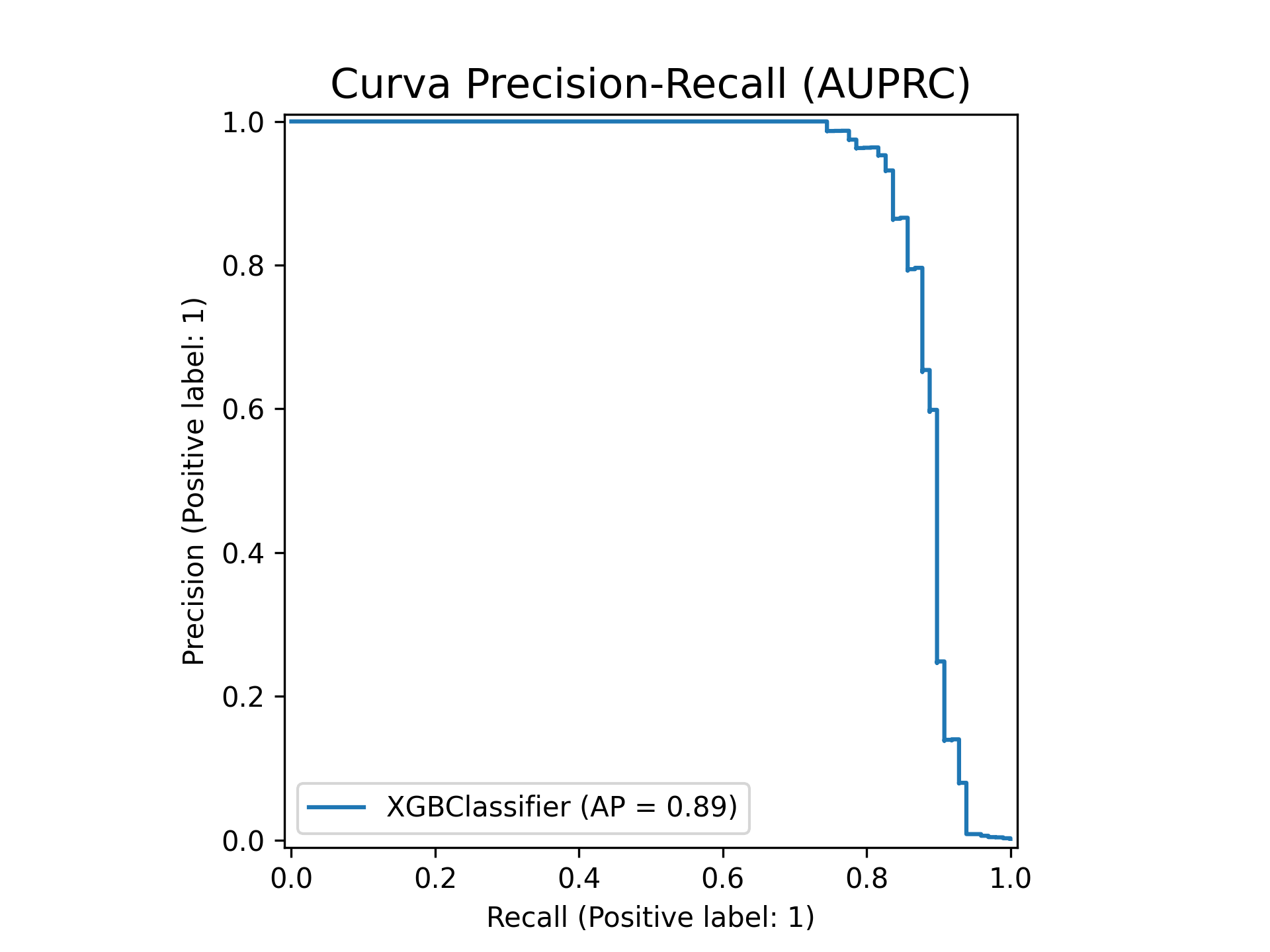
Dado o alto grau de desbalanceamento nós consideramos o resultado atual interessante, AUPRC de 0.8870 é uma métrica que valida a alta qualidade das predições em um cenário de extremo desbalanceamento. O modelo obteve um F1-Score de 0.85 para a classe de fraude, equilibrando com precisão a necessidade de capturar transações suspeitas (Recall de 0.84) com a manutenção de uma baixa taxa de alarmes falsos (Precision de 0.87).
Caso estivéssemos com dados não codificados, poderiamos talvez melhorar o modelo com engenharia de features e mais dedicação a fase de otimização de hiperparâmetros, ainda assim dadas as limitações do dataset foi possível explorar etapas interessantes da construção de um pipeline de ciência de dados dedicado a detecção de fraudes.
Downloads e Links
Repositório GitHub- BROWNLEE, Jason. XGBoost With Python: Gradient Boosted Trees With XGBoost and scikit-learn. Edition v1.15. Machine Learning Mastery, 2020.
- Matthew Wiens, Alissa Verone-Boyle, Nick Henscheid, Jagdeep T. Podichetty, Jackson Burton A Tutorial and Use Case Example of the eXtreme Gradient Boosting (XGBoost) Artificial Intelligence Algorithm for Drug Development Applications. Disponível em: ascpt.onlinelibrary.wiley.com . (Acesso em: 27 fev. 2026)
- PINHEIRO, João Manoel Herrera. Detecção de Fraude em Cartões de Crédito utilizando Técnicas de Machine Learning. 2021. Trabalho de Conclusão de Curso (Bacharelado em Estatística) – Instituto de Matemática e Estatística, USP. Disponível em: bdta.abcd.usp.br . (Acesso em: 27 fev. 2026)
- MACHINE LEARNING GROUP - ULB. Credit Card Fraud Detection Dataset. Disponível em: kaggle.com/mlg-ulb/creditcardfraud . (Acesso em: 27 fev. 2026)